je me suis fait un truc de dingue ... obtenir au format json les données des sites, l'avantage du json est que si un élément n'existe pas, le script se hurle pas, donc pas besoin de try/catch
en plus c'était un exercice de regex pas piqué des hannetons
exemple
function myFunction(){
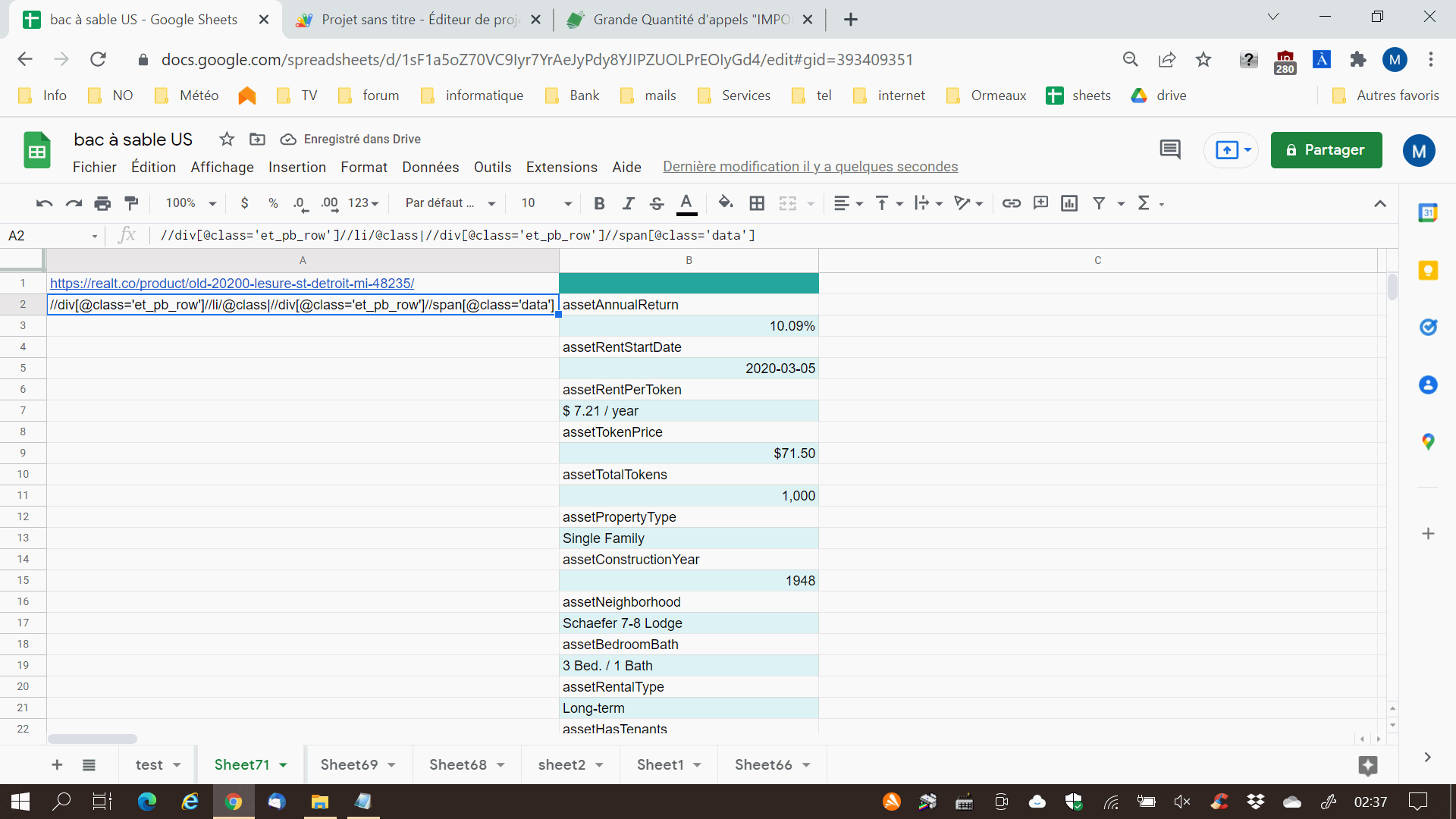
var data = gatDataAsJson('https://realt.co/product/old-20200-lesure-st-detroit-mi-48235/')
Logger.log ([data.truc, data.assetAnnualReturn, data.assetHasTenants, data.assetSection8])
// donne ici [null, 10.09%, Fully Rented, Partial]
}
function gatDataAsJson(marketplaceLink) {
var fetchedUrl = UrlFetchApp.fetch(marketplaceLink, { muteHttpExceptions: true });
if (fetchedUrl) {
var html = fetchedUrl.getContentText().replace(/(\r\n|\n|\r|\t| )/gm, "")
if (html.length) {
var json = {}
var section = html.match(/(<h3 class="blue-title">Property Highlights<\/h3>(.*)<!-- End of Investor ID -->)/g)[0]
var sousSections = section.match(/<li class[\s\S\w]+?<\/li>/g)
sousSections.forEach(function(elem){
var classe = elem.match(/(<li class([^ ]+))/g)[0].match(/"([^"]+)"/g)[0].slice(1,-1)
var donnee = elem.match(/<span class="data">([^<]+)</g)[0].match(/>(.*)</g)[0].slice(1,-1)
json[classe] = donnee
})
// Logger.log(JSON.stringify(json))
return (json)
}
}
}
je vais chercher la section où se situent les données
html.match(/(<h3 class="blue-title">Property Highlights<\/h3>(.*)<!-- End of Investor ID -->)/g)[0]
que je découpe en alinéas
var sousSections = section.match(/<li class[\s\S\w]+?<\/li>/g)
dans lesquels je vais chercher la classe de li et les données dans span
je mets tout cela dans un format json