IMPORTXML <span> "mot" </span
Bonjour !
j'effectue du scrapping sur un site. Comment récupérer le contenue de balise <Span> avec un mot clé spécifique ?
basiquement je recupère le contenu ciblé, ou un contenu global ( =IMPORTXML(site;//span)).
mais j'ai plusieurs balises qui m'intéresse
<span> New! </span>
<span> Reinvestment </span>
<span> Coming Soon! </span>
et je veux recuperer les infos après ces balises ( description produit, titre, prix,.... )
mais j'y arrive pas
pour le moment je cible chaques infos et je fait des formules importxml a chaque fois... ce n'est pas un bon apprentisage !
merci bien !
ps ; voici le site : site ( actuellement je cible sur le "marketplace" mais j'obtiens seulement ce qui est mis en avant, je n'ai pas le reste..)
EDIT : j'ai essayé des choses de ce type vu a droite et a gauche mais.....
//span[text()="New!"]Bonjour,
il vaut mieux cibler l'étage supérieur, qui est li
tu peux faire
=importxml(A1;"//li")ou cibler sur le contenu des class de li
=importxml(A1;"//li[@class[contains(.,'new_product')]]|//li[@class[contains(.,'coming_soon')]]")je n'ai pas trouvé de reinvest, même en regardant comme ceci pour avoir toutes les class des li
=sort(unique(importxml(A1;"//li/@class")))Edit !
en faite j'obtiens le même resultat de mon coté :D
je devrais en avoir une 30aine en "Coming Soon! "
je te partage un doc en page 2
Doc
Il n'y a plus rien en coming soon ... donc j'ai complété la liste
=importxml(A1;"//li[@class[contains(.,'new_product')]]|//li[@class[contains(.,'coming_soon')]]|//li[@class[contains(.,'limited_release')]]|//li[@class[contains(.,'sold_out')]]")et effectivement, l'affichage est limité.
1-
En fait, il y a de l'ajax ( Asynchronous JavaScript And XML) https://developer.mozilla.org/fr/docs/Web/Guide/AJAX/Getting_Started qui permet au site de se compléter au fur et a mesure de la navigation.
2-
et puis on voit aussi que le site possède des données sous forme de json, et c'est cela qu'il faut capter et décoder, notamment dans la partie suivante
/* <![CDATA[ */
.....................................
/* ]]> */
et notamment var realtPortfolioData
ou externe https://realt.co/wp-json/ (mais là il ne s'agit pas de données mais de méthodes d'interrogation post/get avec des urls)
j'essaierai dans la journée de voir ce qu'ils contiennent !
cela semble néanmoins compromis quant à l'interrogation directe du contenu
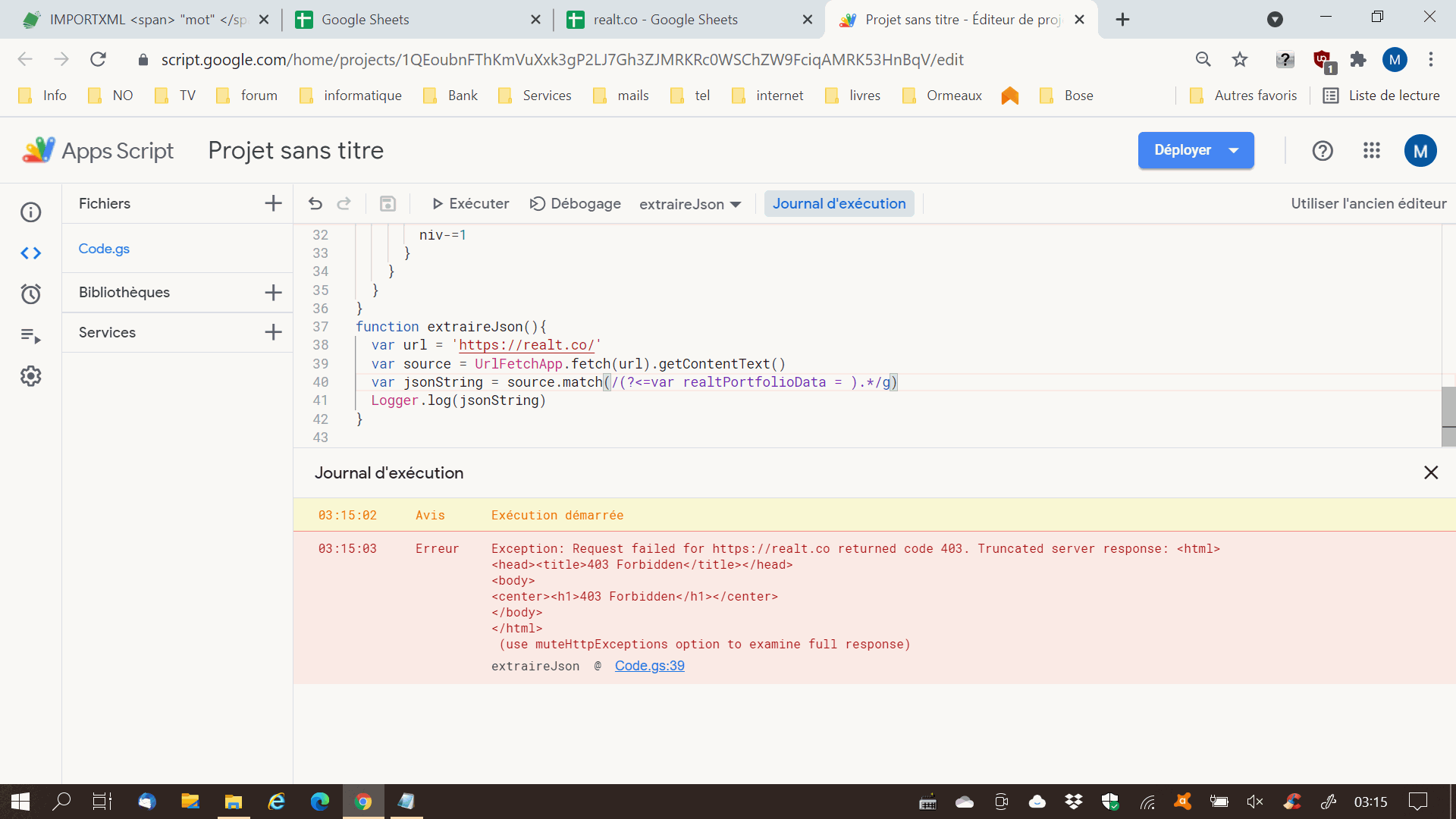
même avec
var source = UrlFetchApp.fetch(url,{muteHttpExceptions: true}).getContentText()donc pas de possibilité ici !
J'ai copié la variable realtPortfolioData dans un fichier et mis sur un serveur ... résultat en mp.
J'ai copié la variable realtPortfolioData dans un fichier et mis sur un serveur ... résultat en mp.
Bonjour, les info présents sur ta page json, je les retrouves déjà sur mon API. Ce sujet
mon intérêt était de trouver en 1x ce que j'ai fait sur mon doc,
en faite j'ai accès à un bot telegram qui scrappe et alerte lorsqu'il y a des ventes de dispo, je suis jaloux
- ouvre le site
- clic droit > afficher la source
- copier/coller ligne 40 à 48 les données (recherche
realtPortfolioData) - dans l'onglet DONNEES, choisis les données voulues
est-ce que cela te donne ce que tu cherches en dehors de l' API CONNECTOR ?
https://docs.google.com/spreadsheets/d/1VsuVe2baeu9pLAvDeCsGR1OnPuAy00cGuoBHg3AIHek/edit?usp=sharing
est-ce que cela te donne ce que tu cherches en dehors de l' API CONNECTOR ?
l'API connector me donne une partie des données ( par rapport a ce que je vois dans ton doc et les infos dispo en colonne F )
En revanche tu as disséqué le site en profondeur
Pour le coup je ne sais pas trop quoi dire, à la base de ce sujet j'étais parti sur un "simple"
["etat *" + "nom" + "prix unitaire"] *etat ( tout sauf "sold out", il doit y avoir "Reinvestment", "New!", et "Release" selon les titres, j'ai un doute sur l'exactitude du dernier)
chose impossible avec un simple importxml pour extraire ces infos le site entier. je l'ai bien compris.
et je suis pas sur d'avoir compris ce que je devais faire, car a partir du code source du site les lignes 40 à 48 ne corresponde pas avec une recherche "realtfoliodata"
Ben, heu,
- regarde déjà dans l'onglet DONNEES en faisant varier la liste déroulante (cellule fond bleu) s'il y a des données qui t'intéressent, on pourra alors faire quelque chose de plus adapté.
- Après, pour remettre à jour ces données, il faudra à chaque fois aller chercher dans le code source de la page les lignes adhoc et les coller à la main dans le script.
ah c'est que je suis en lecture seul ^^' et j'ai pas accès un un menu déroulant. d'ou mon interrogation du coup :)
fais-toi une copie https://docs.google.com/spreadsheets/d/1VsuVe2baeu9pLAvDeCsGR1OnPuAy00cGuoBHg3AIHek/copy
désolé
En effet, je ne voulais pas faire de copie sans ton aval.
Je réalise, qu'il faut que je sois connecté et identifié par le site pour voir certaines informations je pense..
je vois mes certaines de mes informations perso, sur le code source du site lorsque je fait une recherche "realTportfolioData" par ex.
(code source quand je suis connecté sur le site ).
autrement j'arrive a retrouver les titres sur lesquels j'ai vu :
Dans RealTsellTokenL10n
data.Frame.property_statuses.coming_soon
data.Frame.property_statuses.new_product
data.Frame.property_statuses.limited_release
.
Ensuite je peux retrouver dans realTokenSalesData et realtPortfolioData ( donc je penche pour le 1er dans la logique des choses...)
data.properties[X].product_id
data.properties[X].name
data.properties[X].yield
data.properties[X].price
X étant la variable car ça change de numéro pour chaques données
EDIT Je ne vais pas mélanger les sujets.
le sujet visant a remplacer API Connector pour exploiter mon API via un script n'a rien a voir avec ce sujet.
Dans la mesure où tu passes par le navigateur, tu bénéficies de ton login. Du reste (je le précise pour le(s) modérateur(s) ), dès lors que tu peux accéder à ces infos par l'api connector, ce n'est donc pas du web scraping illégal, c'est juste une autre façon d'y aller. Ce site est de quelle "nationalité ?
site US.
effectivement si tout cela pose un problème légal, je comprendrais qu'on stoppe si jamais. Il est vrai que je ne m' étais pas posé la question.
PS : pour avoir ce qui est dans ce sujet, je pense que même sans etre logger, nous y avons accès. vu que ce sont des infos public
si c'est un site US, il n'y a pas de problème ...
Aux États-Unis, la justice estime que les données sont publiques en étant diffusées via Internet et peuvent donc être librement collectées via web scraping.
En Europe, la Cour Européenne a décidé que les entreprises européennes peuvent utiliser les CGU de leur site web pour interdire le scraping de leurs données. La décision s’applique non seulement aux sites web, mais aussi aux applications mobiles et à tout autre type de médias en ligne mettant des données et contenus à la disposition du public.
donc pas de soucis !
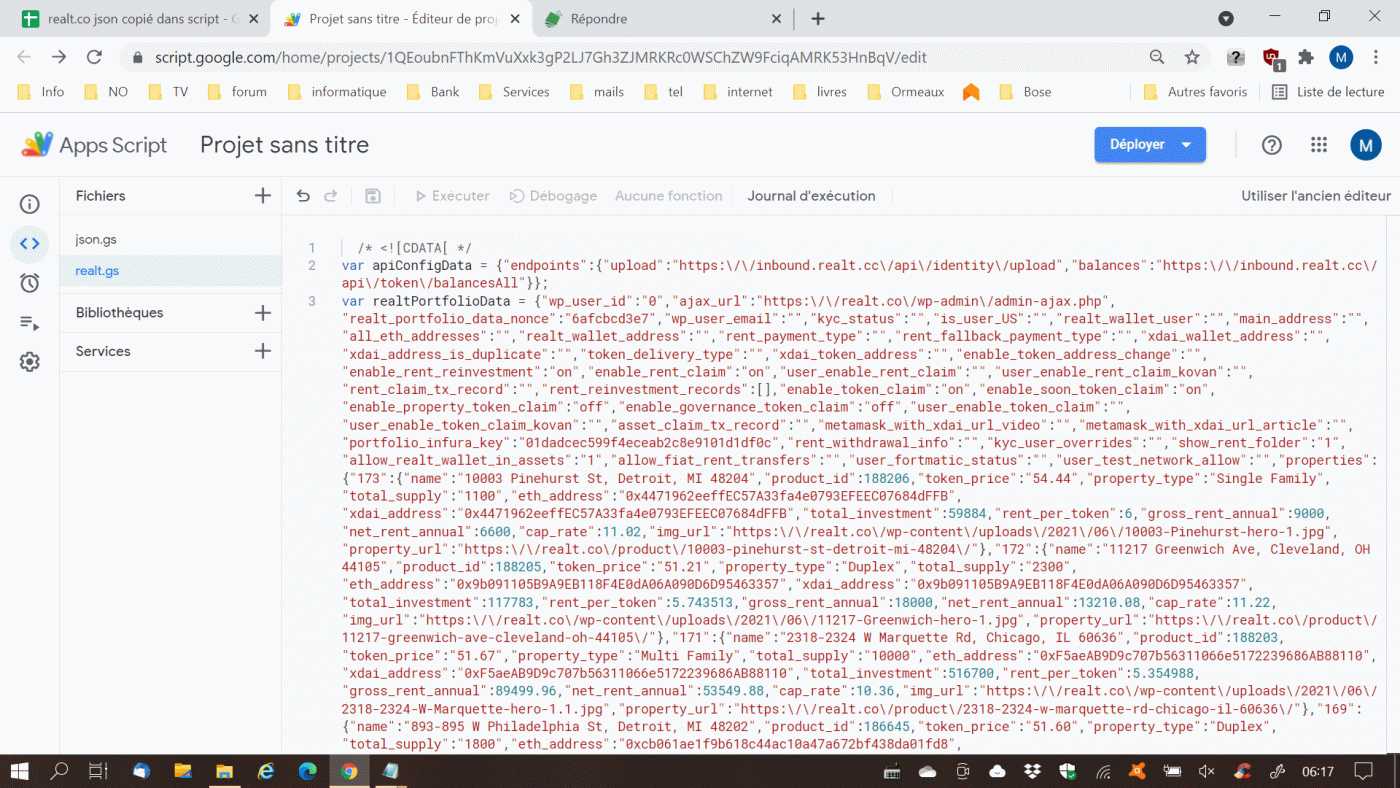
j'ai mis la copie (partielle) du code source dans un script à part, c'est plus simple pour manipuler
et mis aussi un script plus adapté
let resultat = [];
function realt(x){
getAllData(1,eval(x),x)
return resultat
}
function getAllData(niv,obj,id) {
const regex = new RegExp('[^0-9]+');
for (let p in obj) {
var newid = (regex.test(p)) ? id + '.' + p : id + '[' + p + ']';
if (obj[p]!=null){
if (typeof obj[p] != 'object' && typeof obj[p] != 'function'){
resultat.push([niv, (newid), p, obj[p]]);
}
if (typeof obj[p] == 'object') {
if (obj[p].length){
resultat.push([niv, (newid), p + '[0-' +(obj[p].length-1)+ ']', 'tableau']);
}else{
//resultat.push([niv, (newid), p, 'parent']);
}
niv+=1;
getAllData(niv, obj[p], newid );
niv-=1
}
}
}
} 
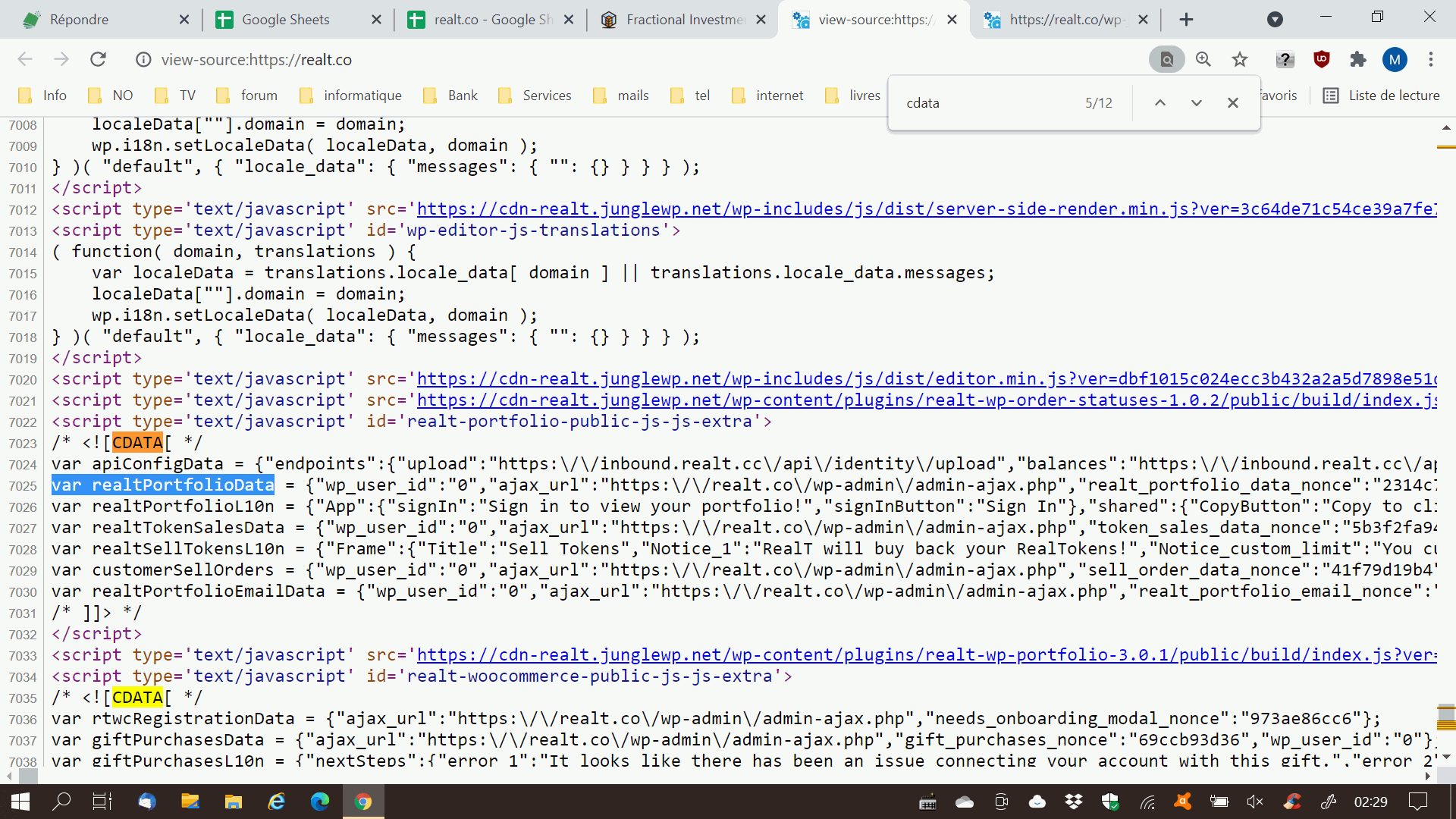
ce que je n'arrive pas a retrouver quelque soit mes recherches c'est la liste des liens
par ex. j'ai :
https://realt.co/listing-category/chicago/
https://realt.co/listing-category/detroit/
etc....
mais je ne retrouve pas la liste complète de ces liens. car au final les infos que je souhaites sont sur ces pages
et le fait qu'il y ai plusieurs pages aussi, c'est un élément bloquant pour tout récupérer d'un coup (en importxml )