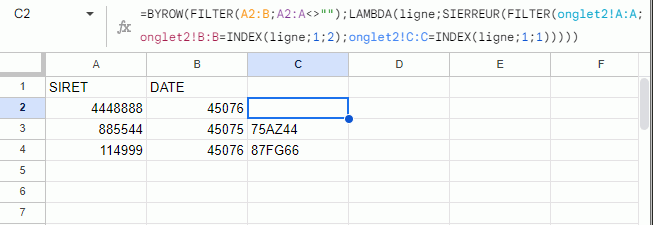
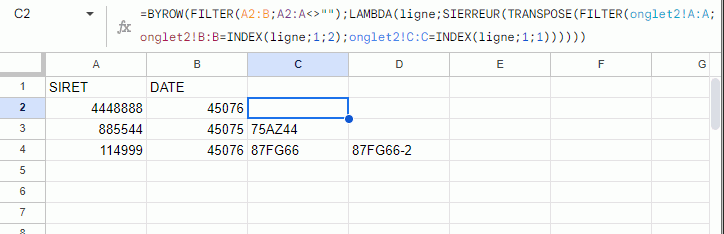
J'ai rajouté un INDEX pour limiter les résultats à 1 par ligne, ça devrait régler ton problème :
=BYROW(FILTER(B2:H;A2:A<>"");LAMBDA(ligne;SIERREUR(INDEX(FILTER(onglet2!A:A;onglet2!D:D=INDEX(ligne;1;1);onglet2!AQ:AQ=INDEX(ligne;1;7));1;1))))
Peux-tu me décrire le déroulé de cette formule ?
Cette fonction filtre de la plage B2:H (en fonction de la colonne A) pour ignorer les lignes vides :
FILTER(B2:H;A2:A<>"")
Donc BYROW va parcourir ici les lignes non vides de la plage B2:H :
BYROW(FILTER(B2:H;A2:A<>"");
Pour chaque ligne, LAMBDA va donc effectuer ce calcul :
SIERREUR(INDEX(FILTER(onglet2!A:A;onglet2!D:D=INDEX(ligne;1;1);onglet2!AQ:AQ=INDEX(ligne;1;7));1;1))
Si on retire SIERREUR que tu connais bien et INDEX qui limite le résultat à 1, il reste :
FILTER(onglet2!A:A;onglet2!D:D=INDEX(ligne;1;1);onglet2!AQ:AQ=INDEX(ligne;1;7))
Donc là la colonne A est filtrée en fonction de la colonne D et AQ (d'où un résultat sur plusieurs lignes possible si les combinaisons ne sont pas uniques dans ta feuille).
Quant aux INDEX(ligne;1;7), ce sont les valeurs du tableau "ligne" (BYROW parcourt la plage en premier argument ligne par ligne).
Car autant en script, je me débrouille
Si tu utilises parfois les méthodes de tableau en Apps Script, tu devrais rapidement être à l'aise avec ce type de fonction (la fonction MAP par exemple c'est l'équivalent de la méthode map). Ce type de fonction peut te faire progresser à la fois en formules et en code.
Juste pour l'exemple, s'il avait fallu créer une fonction personnalisée en utilisant ce type de méthodes, elle aurait pu s'écrire ainsi :
=POUR_PIERRE(A2:H;onglet2!A2:AQ)
function POUR_PIERRE(p1, p2) {
return p1.filter(i => i[0]).map(i => (p2.filter(j => j[3] * 1 == i[1] * 1 && j[42] == i[7])[0] ?? [''])[0]);
}