re
tiens voila tes 3 tableaux identifié
comme la fonction getelementsbyclassname a toujours déraillé aussi loin que je m'en souvienne, on créée un tableau d'object en bouclant sur une classe
Sub test()
Dim lestableaux() As Object
With CreateObject("htmlfile")
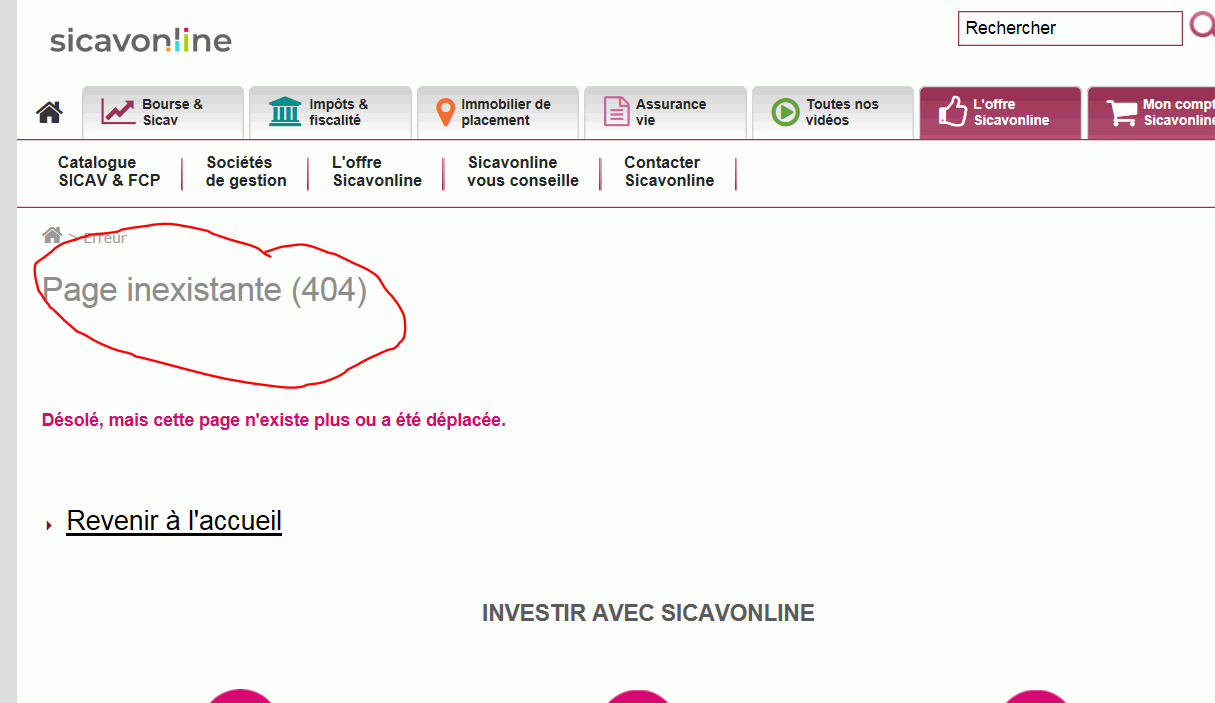
.body.innerhtml = GetHtmlcode("https://www.sicavonline.fr/index.cfm?action=fiche&code=00000X09032")
If Not .body.innerhtml Like "*Page inexistante*" Then
For Each elem In .all
If elem.classname = "bloc_gene_suite" Then ReDim Preserve lestableaux(0 To i): Set lestableaux(i) = elem: i = i + 1
Next
MsgBox "tableau de Performance est volatilité" & vbCrLf & lestableaux(0).innertext 'tableau de Performance est volatilité
MsgBox "tableau de synthese" & vbCrLf & lestableaux(1).innertext 'tableau de synthese
MsgBox "tableau de Point clé" & vbCrLf & lestableaux(2).innertext 'tableau de Point clé
Else
MsgBox "page inexistante"
End If
End With
End Sub
ne reste plus qu'a pecher les element dans les items object de l'array lestableaux ou directement a partir du document si il y a un ID (qui est sensé etre unique)
par exemple la valeur liquidative directe par le document et .getelementbyid
MsgBox "valeur liquidative:" & .getelementbyid("VL").innertext
sinon en le péchant dans le tableau synthese
MsgBox "valeur liquidative:" & lestableaux(1).getelementsbytagname("DIV")(27).innertext
on constate effectivement que ce ne sont pas des tables simples les lignes (pseudo TR/TD)mais ce sont sont des DIVS arrangés en CSS
BREF DONC
pour le tableau synthese par exemple il faut aller chercher la classe "ligne_fiche_val" dans lestableaux(1)
pour récupérer les données