Extraire du texte depuis des données JSON
Bonjour,
A partir de données au format JSON, j'ai récupéré un tableur mais j'aurais besoin de "nettoyer" le texte contenu dans certaines cellules pour faire disparaître le langage JSON.
Par exemple, j'ai une cellule qui contient ce texte :
{u'affiliations': [u'Ecole Polythechnique F\xe9d\xe9rale de Lausanne'], u'name': u'P. Henry'} *** {u'affiliations': [u'Hydroat S.p.A. Milan'], u'name': u'V. Zanetti'} *** {u'affiliations': [u'Neyrpic Grenoble'], u'name': u'M. Wegner'}
et j'aimerais pouvoir récupérer les noms d'auteurs, en l'occurrence : P. Henry, V. Zanetti, M. Wegner
de même pour les affiliations : Ecole Polythechnique F\xe9d\xe9rale de Lausanne, Hydroat S.p.A. Milan, Neyrpic Grenoble
(au passage, s'il y a moyen de corriger les erreurs liées aux accents, je suis preneuse)
J'ai essayé la fonction SPLIT, qui fonctionne bien avec le séparateur *** mais je n'ai pas réussi avec le séparateur "u'name'".
Je vous mets le lien vers le fichier test : https://docs.google.com/spreadsheets/d/18mqgcPDekW_p7IcQs8mWkvBl-fhR6LE9fuDhA05DrSY/edit?usp=sharing
Merci beaucoup pour votre aide !!
Déborah
Bonjour,
pour moi, tes données ne sont pas en json "propre", donc difficile de parser ce json
as-tu le json d'origine ?
voici un code simple pour décoder tout un json
let resultat = [];
function getAllDataJSON(url) {
if (url.match(/http(s)?:\/\/?/g)){var data = JSON.parse(UrlFetchApp.fetch(url).getContentText())}
else{var data = JSON.parse(url)}
getAllData(1,eval(data),'data')
return resultat
}
function getAllData(niv,obj,id) {
const regex = new RegExp('[^0-9]+');
for (let p in obj) {
var newid = (regex.test(p)) ? id + '.' + p : id + '[' + p + ']';
if (obj[p]!=null){
if (typeof obj[p] != 'object' && typeof obj[p] != 'function'){
resultat.push([niv, (newid), p, obj[p]]);
}
if (typeof obj[p] == 'object') {
if (obj[p].length){
resultat.push([niv, (newid), p + '[0-' +(obj[p].length-1)+ ']', 'tableau']);
}else{
//resultat.push([niv, (newid), p, 'parent']);
}
niv+=1;
getAllData(niv, obj[p], newid );
niv-=1
}
}
}
} Bonjour à tous,
Un début de solution en passant pour extraire les noms avec REGEXEXTRACT :
=ARRAYFORMULA(REGEXEXTRACT(SPLIT(B2;"***";0);"name': u'([^']+)'"))Cordialement,
Bonjour,
Merci pour vos réponses !
@Sébastien, j'ai testé et cela permet effectivement d'extraire les noms !
Par contre, si je veux avoir les affiliations (ou les autres paramètres), comment faire ? J'ai testé en remplaçant simplement "name" par "affiliations" mais ça ne marche pas...
@Mikhail : J'ai accès aux fichiers JSON d'origine (j'ai copier coller un fichier ci-dessous avec une capture d'écran partielle en plus pour avoir une mise en forme plus lisible) mais j'ai plusieurs questions dans ce cas :
- comment faire pour utiliser le code que tu donnes ? (je suppose que c'est une macro mais je ne m'en suis jamais servi...)
- j'ai un fichier JSON par article et je vais devoir en traiter environ 5000 : y a-t-il moyen d'automatiser le décodage ?
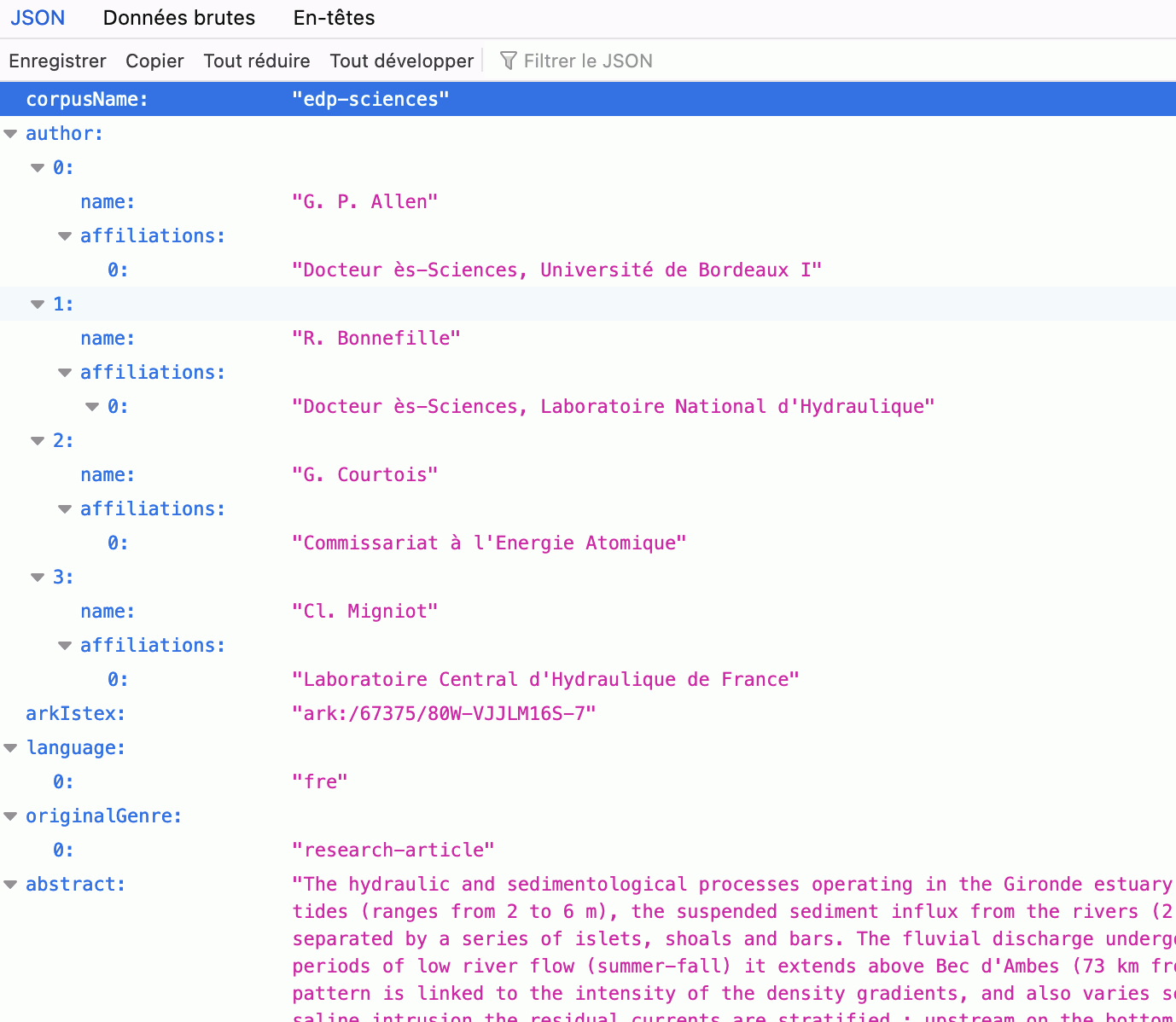
{"corpusName":"edp-sciences","author":[{"name":"G. P. Allen","affiliations":["Docteur ès-Sciences, Université de Bordeaux I"]},{"name":"R. Bonnefille","affiliations":["Docteur ès-Sciences, Laboratoire National d'Hydraulique"]},{"name":"G. Courtois","affiliations":["Commissariat à l'Energie Atomique"]},{"name":"Cl. Migniot","affiliations":["Laboratoire Central d'Hydraulique de France"]}],"arkIstex":"ark:/67375/80W-VJJLM16S-7","language":["fre"],"originalGenre":["research-article"],"abstract":"The hydraulic and sedimentological processes operating in the Gironde estuary (SW France) are linked to the interaction between the river discharge (mean values between 800-1,000 m3/s), tides (ranges from 2 to 6 m), the suspended sediment influx from the rivers (2 to 3 million tons per year), and the general morphology of the estuary, consisting in two channel systems separated by a series of islets, shoals and bars. The fluvial discharge undergoes important seasonal variations, and the length of the salinity intrusion varies correspondingly : during periods of low river flow (summer-fall) it extends above Bec d'Ambes (73 km from the inlet), and during high river flow, below Pauillac (45 km from the inlet). The residual circulation pattern is linked to the intensity of the density gradients, and also varies seasonally, following changes in the ratio of river flow to tidal prism. Generally speaking, in the zone of the saline intrusion the residual currents are stratified : upstream on the bottom, and downstream toward the surface. The channel and shoal topography can locally disrupt the residual currents by amplifying the flood or the ebb flow. The principal null point, or zone of convergence of the bottom residual currents upstream of which the bottom residuals are always oriented downstream, generaly coincides with the upstream extremity of the salinity intrusion, and follows the same seasonal migrations. There is a marked lateral salinity gradient in the lower estuary, with less saline water flowing along the right bank (looking downstream). A well marked \"turbidity maximum\" forms at the upstream limit of the salinity intrusion, in the zone of bottom residual current convergence. This turbidity maximum migrates seasonally, in response to the migration of the salinity intrusion and null point. The concentration of suspended sediment in the turbidity maximum is very high (0.1 to 10 g/l). The deposition of suspended sediment in the main estuarine channel occurs through the formation of pools of extremely turbid bottom water (100-300 g/l). Practically no movement is discernible in these pools of \"fluid mud\", and intense bottom deposition by settling occurs. These pools are formed in the turbid core of the turbidity maximum, in zones of \"motionless lenses\", on the bottom occuring at flood slack by the amplification of the velocity time assymetry in the salinity intrusion. This fluid mud follows a cycle of erosion and deposition linked to the monthly cycle in tidal ranges. During neap tides the mud accumulates, and during spring tides, it is eroded and resuspended into the overlying turbidity maximum. It appears, from suspended sediment flux measurements in the lower estuary, and analysis of the plume of turbid estuarian water escaping out on to the continental shelf during river floods and spring tides, that a significant amount of alluvial suspended sediment bypasses the estuary and is deposited in a silt and olay zone on the inner continental shelf. Possibly part of this estuarine water is recirculated in an estuarine and lagoonal system further north. In order to study and assess the diffusion of the fluid mud into the turbidity maximum during spring tides, and also to follow the upstream migration of these fluid mud pools during a period of decreasing river discharge, a radioactive tracer study was made of the fluid mud. This study showed that a very slow movement, on the order of 0.1-0.2 cm/s occurs in the fluid mud, and appears to be directed downstream. Also it was shown that at each cycle of erosion and deposition of the fluid mud, which reformed further upstream at each cycle, the same sediment appears to be recycled.","qualityIndicators":{"score":10,"pdfWordCount":6075,"pdfCharCount":30498,"pdfVersion":1.6,"pdfPageCount":8,"pdfPageSize":"601.68 x 846 pts","pdfWordsPerPage":759,"pdfText":true,"refBibsNative":false,"abstractWordCount":593,"abstractCharCount":3691,"keywordCount":0},"title":"Processus de sédimentation des vases dans l'estuaire de la Gironde Contribution d'un traceur radioactif pour l'étude du déplacement des vases","refBibs":[],"genre":["research-article"],"host":{"title":"La Houille Blanche","language":["unknown"],"issn":["0018-6368"],"eissn":["1958-5551"],"publisherId":["lhb"],"issue":"1-2","pages":{"first":"129","last":"136","total":"8"},"genre":["journal"]},"ark":["ark:/67375/80W-VJJLM16S-7"],"categories":{"wos":["1 - science","2 - water resources"],"scienceMetrix":["1 - applied sciences","2 - engineering","3 - environmental engineering"],"scopus":["1 - Physical Sciences","2 - Environmental Science","3 - Water Science and Technology"],"inist":["1 - sciences appliquees, technologies et medecines","2 - sciences biologiques et medicales","3 - sciences biologiques fondamentales et appliquees. psychologie"]},"publicationDate":"1974","copyrightDate":"1974","enrichments":{"type":["grobidFulltext","multicat","nb"]},"doi":["10.1051/lhb/1974013"],"_id":"2F0EAFCFAE1716C93DB7ECC71EDD4EDE9CB1E132"}Merci beaucoup pour votre aide !!
Déborah
Voici un exemple complet d'extraction des données du json https://docs.google.com/spreadsheets/d/1UF31unCHqB910hr-8nqGPv82MBm6tAxLWPPwQWuzhTg/copy
Tu peux mettre en A1 soit le json, soit l'url du json.
On peut cibler quelques données et dans ce cas l'accès se fait (sauf particularité) par le code de la colonne B.
Je reprendrai le sujet dans la journée en ciblant un code sur quelques données.
On peut faire une fonction paramétrée, mais si tu as 5000 json à décoder, je pense qu'il faudrait plutôt faire un script pour éviter qu'à chaque ouverture de fichier la fonction se mette en route (et bloque par dépassement de temps côté serveur).
Donne les informations que tu souhaites retenir.
Bonjour,
Merci Mikhail !!
Les données qui m'intéressent vraiment (classées par ordre d'importance si jamais cela faisait encore trop) :
- data._id
- data.author / name (tous les noms)
- data.author / affiliations (toutes les affiliations)
- data.publicationDate
- data.title
- data.abstract
- data.host.issue
- data.categories.scopus (toutes)
- data.originalGenre ou data.genre
-data.doi
Merci encore pour ton aide !
Déborah
ok
Ce n'est pas une question de quantité, mais plus de présentation des résultat car il peut y avoir des occurrences multiples ... et des sous-occurrences multiples (plusieurs auteurs avec chacun potentiellement plusieurs affiliations) ... je vais te proposer quelque chose qui "rentre" dans un tableau à 2 dimensions.
Mais une autre solution pour les affiliations serait de produire une autre feuille car elle ne sont pas liées au document mais à l'auteur lui-même.
Projet ... tu as un menu en haut à droite
Les url ou données sont ici en B1, on verra pour ensuite multiplier les url ou données

function onOpen() {
var ui = SpreadsheetApp.getUi();
ui.createMenu('** MENU **')
.addItem('Extraire les ifnormations', 'extraire')
.addToUi();
}
function extraire(){
var f=SpreadsheetApp.getActiveSpreadsheet().getSheetByName('extraire')
var url=f.getRange('B1').getValue()
if (url.match(/http(s)?:\/\/?/g)){
var data = JSON.parse(UrlFetchApp.fetch(url).getContentText())
}
else{
var data = JSON.parse(url)
}
var donnees=f.getRange('A2:A10').getValues()
var result=[]
donnees.forEach(function(elem){
if (typeof eval(elem[0])=='string'){
result.push(eval(elem[0]))
}else{
var txt=''
eval(elem[0]).forEach(function(selem){
// partie spécifique
if(selem.name!=null){
txt+=(selem.name)
txt+= ' : ' + (selem.affiliations) + '\n'
}else{
txt+=(selem) + '\n'
}
})
result.push(txt)
}
})
f.getRange(2,2,result.length,1).setValues(transpose([result]))
}
function transpose(a){
return Object.keys(a[0]).map(function (c) { return a.map(function (r) { return r[c]; }); });
}https://docs.google.com/spreadsheets/d/1Ma0ldWH_e5-OGMRnLNvKaFOWk0dENzEeadisNbricTQ/copy
Bonjour,
Merci pour cette proposition !
J'ai plusieurs questions :
- est-il possible de séparer les noms et affiliations des auteurs dans deux cases différentes ? et de prévoir un séparateur clair (ex : ***)
- serait-il possible de transposer le tableau pour que les catégories soient en colonnes et non en ligne ?
- quelle est la procédure à suivre ensuite pour traiter tous mes fichiers JSON ? et peut-on les mettre tous dans le même fichier Gsheet ?
Merci !
Déborah
Merci pour ces réponses ... cela éclaircit la suite :
- est-il possible de séparer les noms et affiliations des auteurs dans deux cases différentes ? et de prévoir un séparateur clair (ex : ***)
oui, mais tu es consciente qu'il peut y avoir plusieurs noms, je les mets dans la même case ? et à côté les affiliations ?
- serait-il possible de transposer le tableau pour que les catégories soient en colonnes et non en ligne ?
sans problème, j'y pensais justement
- quelle est la procédure à suivre ensuite pour traiter tous mes fichiers JSON ? et peut-on les mettre tous dans le même fichier Gsheet ?
est-ce que tu pars d'url ou de contenu textuel ?
"oui, mais tu es consciente qu'il peut y avoir plusieurs noms, je les mets dans la même case ? et à côté les affiliations ?"
=> oui, il peut y avoir plusieurs noms dans la même case, du moment que le séparateur est clair. Les affiliations dans une autre case si possible.
" est-ce que tu pars d'url ou de contenu textuel ?"
=> j'ai des fichiers JSON téléchargés sur mon ordi, à partir du site ISTEX qui recense beaucoup de documents scientifiques et sur lequel on peut choisir le format de téléchargement (JSON en l'occurence)
Il y a une formule en K1 pour séparer les auteurs de leur affectations, je réfléchis pour séparer aussi les affectations mais cela me semble compliqué car le json admet plusieurs affectations pour le même auteur
Empile les différents json à compter de A2
https://docs.google.com/spreadsheets/d/1Ma0ldWH_e5-OGMRnLNvKaFOWk0dENzEeadisNbricTQ/copy
Merci mais comment fait-on pour "empiler" les fichiers JSON ??
Mets soit l'url, soit les données json dans les cases en partant de A2 pour le premier json, A3 pour le second, A4 pour le suivant ... éventuellement donne moi 3 ou 4 json comme tu l'as fait pour le premier.
Bonjour,
J'ai copié-coller le contenu de deux fichiers JSON en A3 et A4 et lancé le script, mais les colonnes suivantes restent vides...
D'autre part, y aurait-il un moyen d'automatiser cet import de fichiers JSON (je vais en avoir 5000 à traiter !!) ? sachant qu'ils ne sont pas en ligne mais sur mon ordinateur
Merci !!
Déborah
J'ai copié-coller le contenu de deux fichiers JSON en A3 et A4 et lancé le script, mais les colonnes suivantes restent vides...
Peux-tu me passer (en mp si besoin) ton fichier
D'autre part, y aurait-il un moyen d'automatiser cet import de fichiers JSON (je vais en avoir 5000 à traiter !!) ? sachant qu'ils ne sont pas en ligne mais sur mon ordinateur
Oui à condition de connaître les urls ou savoir de où ils proviennent.