Extraire des caractères d'une BDD
Le dernier message n'a pas voulu embarquer le fichier...
Ben, toujours pas...
Faudra bien que fasses du copier-coller sur le dernier fichier que tu m'as envoyé!
A+
Salut tout le monde,
Bon dimanche!
dernière version de ton fichier.
- un double-clic démarre la macro ;
- 3 colonnes d'affichage, histoire de suivre le processus :
* en [B], phase A du traitement avant comparaison (phase B) avec les terminaisons latines (voir plus loin) ;
* en [C], le résultat final actuel ;
- la phase B du traitement s'applique à dénicher les derniers intrus (découvreurs) en comparant les fins de mots avec une liste empirique de terminaisons "latines" ;
- les 2 premiers termes sont actuellement conservés d'office mais il y a alors des intrus (AGLAONEMA SCHOTT) ;
- je ne conserve ici (vachement plus simple à programmer) que VAR. et SUBSP. comme abréviations ou initiales marquées d'un "." ;
- du coup, certains "F." séparant les 2e et 3e termes ont disparu dans l'aventure et ne sachant pas comment choisir en VAR. et SUBSP. ...
Pas trop mécontent!
Je t'ai laissé des commentaires pour suivre mon raisonnement.
Private Sub Worksheet_BeforeDoubleClick(ByVal Target As Range, Cancel As Boolean)
'
Dim tData, tSplit, arrTerm()
Dim sData As String, iFlag%
'
Cancel = True
'
arrTerm = Array("UM", "US", "II", "IS", "ENS", "NA", "ICA", "ENSE", "IA", "EA", "TA", "AE", "ANS", "ERA", "OIDES", "ERI", "OS", "IAS", "NI")
Range("B2:C" & Range("B" & Rows.Count).End(xlUp).Row).ClearContents
tData = Range("A2:B" & Range("A" & Rows.Count).End(xlUp).Row).Value
For x = 1 To UBound(tData, 1)
sData = Trim(tData(x, 1)) 'Phase A
If InStrRev(sData, "- ") > 0 Then sData = Right(sData, Len(sData) - (InStrRev(sData, "- ") + 1)) 'retrait de la partie précédant "-"
If InStrRev(sData, "+ ") > 0 Then sData = Right(sData, Len(sData) - (InStrRev(sData, "+ ") + 1)) 'retrait de la partie précédant "+"
If InStr(sData, "(") > 0 Then sData = RTrim(Left(sData, InStr(sData, "(") - 1)) 'retrait de la partie excédant "("
If InStr(sData, "[") > 0 Then sData = RTrim(Left(sData, InStr(sData, "[") - 1)) 'retrait de la partie excédant "["
If InStr(sData, " EX ") > 0 Then sData = RTrim(Left(sData, InStr(sData, " EX ") - 1)) 'retrait de la partie excédant "EX"
For y = 1 To 2
If InStr(sData, IIf(y = 1, ",", " &")) > 0 Then 'retrait de la partie excédant la première "," et " &"
sData = RTrim(Left(sData, InStr(sData, IIf(y = 1, ",", " &")) - 1))
sData = RTrim(Left(sData, InStrRev(sData, Chr(32)) - 1))
End If
Next
tSplit = Split(sData, Chr(32))
sData = ""
For y = 0 To UBound(tSplit) 'retrait des abrév. sauf VAR. et SUBSP.
If (InStr(tSplit(y), ".") > 0 And (tSplit(y) = "VAR." Or tSplit(y) = "SUBSP.")) Or (InStr(tSplit(y), ".") = 0 And tSplit(y) <> "") Then _
sData = sData & tSplit(y) & Chr(32)
Next
tData(x, 1) = RTrim(sData) 'Phase B
tSplit = Split(tData(x, 1)) 'traitement des derniers découvreurs
sData = tSplit(0) & Chr(32)
If UBound(tSplit) >= 1 Then sData = sData & tSplit(1) & Chr(32) 'les 2 premiers termes sont conservés d'office
For y = 2 To UBound(tSplit)
If Right(tSplit(y), 1) = "." Or tSplit(y) = "X" Or Right(tSplit(y - 1), 1) = "." Then '"X" + VAR., SUBSP. et termes précédents
sData = sData & tSplit(y) & Chr(32)
Else 'sinon, on compare les autres termes avec...
For Z = 0 To UBound(arrTerm) '...la liste des terminaisons latines
If Len(tSplit(y)) >= Len(arrTerm(Z)) Then _
If Right(tSplit(y), Len(arrTerm(Z))) = arrTerm(Z) Then sData = sData & tSplit(y) & Chr(32)
Next
End If
Next
tData(x, 2) = RTrim(sData)
Next
Range("B2").Resize(UBound(tData, 1), 2).Value = tData 'affichage [A] Données originales, [B] Phase A, [C] Phase B
'Columns("B:C").AutoFit
'
End SubSi le fichier s'entête à ne pas vouloir embarquer, il te faudra copier-coller le code ci-dessus dans le module VBA de la feuille contenant les données originales, évidemment.
A+
Bonsoir,
Alors je suis ébahis par ce que je vois !
Sur les 145 000 lignes, il n'y a pratiquement plus aucune erreur ! Tous les noms des découvreurs ont disparus.
Je n'ai repéré qu'un seul type d'erreur :
Rarement, mais ça arrive, certains hybrides notés " nom x nom" perdent le second ; il ne reste alors que "nom x .. " comme on peut le voir sur l'exemple ci-après.
Chenopodium x bontei Aellen, 1933 - DYSPHANIA X BONTEI (AELLEN) STACE, 2009 DYSPHANIA X BONTEI DYSPHANIA X
En ce qui me concerne, ce sont des hybrides qui vont être retirés de la liste car inutilisés à mon échelle. Ils ne semblent pas utilisés d'ailleurs.
Merci beaucoup ; et merci pour les annotations à côté du code !!
Bonne soirée.
Le Drosophile a écrit :Tous les noms des découvreurs ont disparus.
comment ? Christophe Colomb et Vasco de Gama aussi ? alors faut aller redécouvrir l'Amérique et les Indes orientales ?
ça y'en a être grande cataschtroumpf si tous les noms des Grands Explorateurs ont été rayés de l'Histoire !
alors moi aussi, La Drosophile, j'ai été ébahi par ce que j'ai lu !
dhany
Bonjour,
Une proposition à étudier.
A partir du fichier TAXREFv11.txt, et des colonnes NOM_VALIDE et LB_AUTEUR.
Exemples de résultats :
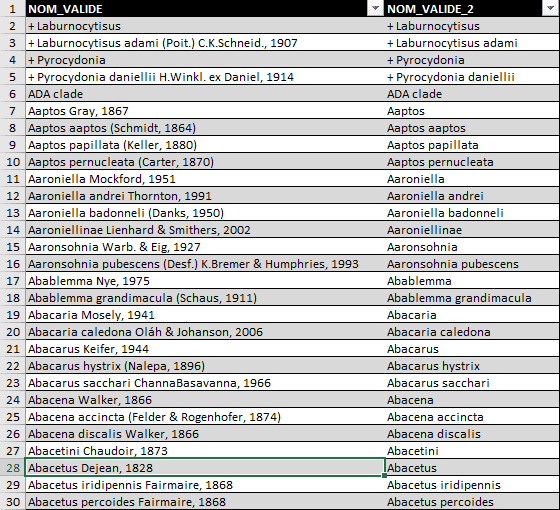
Salut Le Drosophile,
quelques petites imperfections en moins...
- le terme suivant un "X" est intégré d'office ;
- intrus éliminé plus sûrement en phase A ;
- termes entourés d'apostrophes intégré d'office.
Private Sub Worksheet_BeforeDoubleClick(ByVal Target As Range, Cancel As Boolean)
'
Dim tData, tSplit, arrTerm()
Dim sData As String, iFlag%
'
Cancel = True
'
arrTerm = Array("UM", "US", "II", "IS", "ENS", "NA", "EI", "ICA", "IES", "AI", "ACA", "MA", "RA", "YI", "ENSE", "IA", "EA", "TA", "AE", "ANS", "ERA", "OIDES", "ERI", "OS", "IAS", "NI")
Range("B2:C" & Range("B" & Rows.Count).End(xlUp).Row).ClearContents
tData = Range("A2:B" & Range("A" & Rows.Count).End(xlUp).Row).Value
For x = 1 To UBound(tData, 1)
sData = Trim(tData(x, 1)) 'Phase A
If InStrRev(sData, "- ") > 0 Then sData = Right(sData, Len(sData) - (InStrRev(sData, "- ") + 1)) 'retrait de la partie précédant "-"
If InStrRev(sData, "+ ") > 0 Then sData = Right(sData, Len(sData) - (InStrRev(sData, "+ ") + 1)) 'retrait de la partie précédant "+"
If InStr(sData, "(") > 0 Then sData = RTrim(Left(sData, InStr(sData, "(") - 1)) 'retrait de la partie excédant "("
If InStr(sData, "[") > 0 Then sData = RTrim(Left(sData, InStr(sData, "[") - 1)) 'retrait de la partie excédant "["
For y = 1 To 3
If InStr(sData, IIf(y = 1, " EX ", IIf(y = 2, " & ", ","))) > 0 Then 'retrait de la partie excédant "," et " &" et " EX "
sData = RTrim(Left(sData, InStr(sData, IIf(y = 1, " EX ", IIf(y = 2, " & ", ","))) - 1))
sData = RTrim(Left(sData, InStrRev(sData, Chr(32)) - 1))
End If
Next
tSplit = Split(sData, Chr(32))
sData = ""
For y = 0 To UBound(tSplit) 'retrait des abrév. sauf VAR. et SUBSP.
If (InStr(tSplit(y), ".") > 0 And (tSplit(y) = "VAR." Or tSplit(y) = "SUBSP.")) Or _
(InStr(tSplit(y), ".") = 0 And tSplit(y) <> "") Then sData = sData & tSplit(y) & Chr(32)
Next
tData(x, 1) = RTrim(sData) 'Phase B
tSplit = Split(tData(x, 1)) 'traitement des derniers découvreurs
sData = tSplit(0) & Chr(32)
If UBound(tSplit) >= 1 Then sData = sData & tSplit(1) & Chr(32) 'les 2 premiers termes sont conservés d'office
For y = 2 To UBound(tSplit)
If Right(tSplit(y), 1) = "." Or Right(tSplit(y - 1), 1) = "." Or _
Right(tSplit(y), 1) = "'" Or tSplit(y) = "X" Or tSplit(y - 1) = "X" Then 'intègre d'office "X" et terme suivant + VAR., SUBSP. et terme suivant
sData = sData & tSplit(y) & Chr(32) 'intègre d'office termes entre apostrophes " ' "
Else 'sinon, on compare les autres termes avec...
For Z = 0 To UBound(arrTerm) '...la liste des terminaisons latines
If Len(tSplit(y)) >= Len(arrTerm(Z)) Then _
If Right(tSplit(y), Len(arrTerm(Z))) = arrTerm(Z) Then sData = sData & tSplit(y) & Chr(32)
Next
End If
Next
tData(x, 2) = RTrim(sData)
Next
Range("B2").Resize(UBound(tData, 1), 2).Value = tData 'affichage [A] Données originales, [B] Phase A, [C] Phase B
'Columns("B:C").AutoFit
'
End SubUn collègue malin a importé ton TAXREF...
Il y a là tout ce qu'il fallait, déjà nettoyé!!!
A+
Bonjour,
Une proposition à étudier.
A partir du fichier TAXREFv11.txt, et des colonnes NOM_VALIDE et LB_AUTEUR.
Exemples de résultats :
snip_20180806055815.png
Bonsoir,
Si je comprends bien, vous avez utilisé la base de donnée "NOM_VALIDE" et avez supprimé les découvreurs en utilisant la colonne "LB AUTEUR". Donc, dès qu'un auteur apparaît ; il est supprimé dans l'autre colonne.
Si c'est bien ça, difficile de s'assurer que tous les auteurs sont supprimés ; mais visiblement ça fonctionne tout à fait !
En l'occurrence vous avez utilisé le TAXREF complet ; donc les auteurs de l'ensemble des compartiments biologiques ont été retirés.
Un collègue malin a importé ton TAXREF...
Il y a là tout ce qu'il fallait, déjà nettoyé!!!
Non, il ne s'agit pas de la même colonne :
NOM_COMPLET = LB_NOM + LB_AUTEUR
Dans TAXREF ce n'est pas nettoyé.
Ce que je recherchais à faire s'applique sur la colonne NOM_VALIDE ; qui hélas n'a pas été nettoyée.
Par contre il a peut-être utilisé la colonne "LB AUTEUR" pour nettoyer la colonne "NOM VALIDE" qui potentiellement contient les mêmes noms de découvreurs.
Je viens de faire le test avec la formule SUBSTITUE() et ça fonctionne, sauf que ça ne fait les modifications qu'une seule fois... Si la ligne est répétées 5 fois, seule la première est nettoyée, les autres ne le sont pas bizarrement
Bonne soirée.
Salut Le Drosophile,
le collègue a importé sur Excel la version 11 du TAXREF depuis le site ICPN.
Je te mets en fichier quelques lignes du fichier : ce qui t'intéresse est en colonne [O:O]
A+
Bonjour,
Le tout a été réalisé avec Power Query.
Après le commentaire du drosophile sur l'utilisation de NOM_VALIDE (diminué de LB_AUTEUR).
La formule est :
if Text.Contains([NOM_VALIDE],[LB_AUTEUR]) then Text.Replace([NOM_VALIDE],[LB_AUTEUR],"") else [NOM_VALIDE]jmd appellera cela du codage
J'ai au préalable supprimé les doublons NOM_VALIDE (254 ald 550.000 lignes)
A te relire pour un complément d'informations (pour reproduire la chose
Du moins, si les résultats sont ceux attendus…
Cdlt.
Salut Le Drosophile,
le collègue a importé sur Excel la version 11 du TAXREF depuis le site ICPN.
Je te mets en fichier quelques lignes du fichier : ce qui t'intéresse est en colonne [O:O]
A+
Il ne s'agit pas de la bonne colonne. Comme je disais précédemment je cherche à traiter NOM_VALIDE mais là il s'agit visiblement de la colonne "NOM_COMPLET".
Sur ton document, ce serait donc la colonne : S:S.
Par contre avec tes lignes de code, tu as résolu le problème :
[quote]quelques petites imperfections en moins...
- le terme suivant un "X" est intégré d'office ;
- intrus éliminé plus sûrement en phase A ;
- termes entourés d'apostrophes intégré d'office.
Private Sub Worksheet_BeforeDoubleClick(ByVal Target As Range, Cancel As Boolean)
'
Dim tData, tSplit, arrTerm()
Dim sData As String, iFlag%
'
Cancel = True
'
arrTerm = Array("UM", "US", "II", "IS", "ENS", "NA", "EI", "ICA", "IES", "AI", "ACA", "MA", "RA", "YI", "ENSE", "IA", "EA", "TA", "AE", "ANS", "ERA", "OIDES", "ERI", "OS", "IAS", "NI")
Range("B2:C" & Range("B" & Rows.Count).End(xlUp).Row).ClearContents
tData = Range("A2:B" & Range("A" & Rows.Count).End(xlUp).Row).Value
For x = 1 To UBound(tData, 1)
sData = Trim(tData(x, 1)) 'Phase A
If InStrRev(sData, "- ") > 0 Then sData = Right(sData, Len(sData) - (InStrRev(sData, "- ") + 1)) 'retrait de la partie précédant "-"
If InStrRev(sData, "+ ") > 0 Then sData = Right(sData, Len(sData) - (InStrRev(sData, "+ ") + 1)) 'retrait de la partie précédant "+"
If InStr(sData, "(") > 0 Then sData = RTrim(Left(sData, InStr(sData, "(") - 1)) 'retrait de la partie excédant "("
If InStr(sData, "[") > 0 Then sData = RTrim(Left(sData, InStr(sData, "[") - 1)) 'retrait de la partie excédant "["
For y = 1 To 3
If InStr(sData, IIf(y = 1, " EX ", IIf(y = 2, " & ", ","))) > 0 Then 'retrait de la partie excédant "," et " &" et " EX "
sData = RTrim(Left(sData, InStr(sData, IIf(y = 1, " EX ", IIf(y = 2, " & ", ","))) - 1))
sData = RTrim(Left(sData, InStrRev(sData, Chr(32)) - 1))
End If
Next
tSplit = Split(sData, Chr(32))
sData = ""
For y = 0 To UBound(tSplit) 'retrait des abrév. sauf VAR. et SUBSP.
If (InStr(tSplit(y), ".") > 0 And (tSplit(y) = "VAR." Or tSplit(y) = "SUBSP.")) Or _
(InStr(tSplit(y), ".") = 0 And tSplit(y) <> "") Then sData = sData & tSplit(y) & Chr(32)
Next
tData(x, 1) = RTrim(sData) 'Phase B
tSplit = Split(tData(x, 1)) 'traitement des derniers découvreurs
sData = tSplit(0) & Chr(32)
If UBound(tSplit) >= 1 Then sData = sData & tSplit(1) & Chr(32) 'les 2 premiers termes sont conservés d'office
For y = 2 To UBound(tSplit)
If Right(tSplit(y), 1) = "." Or Right(tSplit(y - 1), 1) = "." Or _
Right(tSplit(y), 1) = "'" Or tSplit(y) = "X" Or tSplit(y - 1) = "X" Then 'intègre d'office "X" et terme suivant + VAR., SUBSP. et terme suivant
sData = sData & tSplit(y) & Chr(32) 'intègre d'office termes entre apostrophes " ' "
Else 'sinon, on compare les autres termes avec...
For Z = 0 To UBound(arrTerm) '...la liste des terminaisons latines
If Len(tSplit(y)) >= Len(arrTerm(Z)) Then _
If Right(tSplit(y), Len(arrTerm(Z))) = arrTerm(Z) Then sData = sData & tSplit(y) & Chr(32)
Next
End If
Next
tData(x, 2) = RTrim(sData)
Next
Range("B2").Resize(UBound(tData, 1), 2).Value = tData 'affichage [A] Données originales, [B] Phase A, [C] Phase B
'Columns("B:C").AutoFit
'
End Sub
[/quote]
Ça ça marche.
@Jean-Eric : Oui plusieurs méthodes ont été exploitées et le résultat est bon.
Avec PowerQuery ça fonctionne aussi apparemment ; par contre je ne vois pas comment on fait ça.
Est-ce que ceci fonctionne :
if Text.Contains([NOM_VALIDE],[LB_AUTEUR]) then Text.Replace([NOM_VALIDE],[LB_AUTEUR],"") else [NOM_VALIDE]
Car je n'ai pas vraiment trouvé de moyen de l'utiliser.
Est-ce que vous pourriez me dire pourquoi lorsque j'utilise la formule Substitue(), lorsqu'il y a des doublons, seules les 1ères valeurs sont remplacées, je me retrouve avec la 1ère ligne corrigée et toutes les autres, similaires, non corrigées.
Exemple en PJ.
Bonne journée !
Re,
Pour la solution Récupérer et Transformer (Power Query) :
1 - Ouvre un classeur vierge
2 - Ruban, Données, Récupérer et transformer, Nouvelle requête, A partir d'un fichier, A partir d'un fichier texte.
3 - Sélectionne le fichier TAXREFv11.txt
4 - Une fenêtre s'ouvre avec l'aperçu du fichier texte.
5 - Faire Modifier
L'éditeur Power Query est ouvert.
6 - Sélectionne les colonnes LB_AUTEUR et NOM_VALIDE (comme dans Excel) puis clic droit : Supprimer d'eutres colonnes (liste déroulante)
7 - Sélectionne la colonne NOM_VALIDE et effectue un tri ascendant (idem Excel)
8 - Toujours avec cette colonne sélectionnée, clic droit et Supprimer les doublons.
9 - Dans le ruban, Ajouter une colonne, Colonne personnalisée
10 - Nomme la nouvelle colonne NOM_VALIDE2 (au lieu de Personnalisé) et copie cette formule :
=if Text.Contains([NOM_VALIDE],[LB_AUTEUR]) then Text.Replace([NOM_VALIDE],[LB_AUTEUR],"") else [NOM_VALIDE]Valide avec OK
11 - Sélectionne la colonne LB_AUTEUR, clic droit et Supprimer
12 - Dans le ruban, Accueil, Fermer et charger, Fermer et charger
C'est terminé !...
Bonjour,
Pas de retour ?
Cdlt.
Bonsoir,
Je n'étais pas chez moi ; je vais tester votre méthode.
EDIT :
Bon eh bien après test, ça marche très bien ! Merci beaucoup pour les explications, c'est grâce à ces posts qu'on peut apprendre des choses très utiles !
Je vais enregistrer la réponse sur un document texte de façon à pouvoir m'en resservir lorsque ce sera nécessaire.
Bonne soirée !
Les tests fait sur la BDD TaxRef v11 sont bons, mais dès que j'essai d'appliquer cette solution à mon document, ça ne fonctionne plus.
NOM_VALIDE et NOM_VALIDE_2 sont identiques.
EDIT :
Ah, je comprend, ça fonctionne maintenant.
Je constate que cette solution revient à utiliser cette formule : =SUBSTITUE(A2;B$2:B$12000;"")
Où : la colonne A contient les noms d'espèce, qui sont traités les uns après les autres.
et la colonne B 2 - 12 000 contient la liste des noms des auteurs.
Qui, de la même façon ne permet pas de supprimer plusieurs fois le même nom d'auteur.
Dans la démarche que vous expliquez, il y a une étape qui consiste à supprimer les doublons. J'aimerais les conserver, sauf qu'en les gardant, Excel ne supprime le nom d'auteur qu'une seule fois.
Je n'ai rien trouvé (hormis les propositions à base de Code VBA) qui permette de supprimer plusieurs fois le même nom d'auteur en cas de doublons.
Bonne soirée !